Are data model bias and variance a challenge with unsupervised learning. 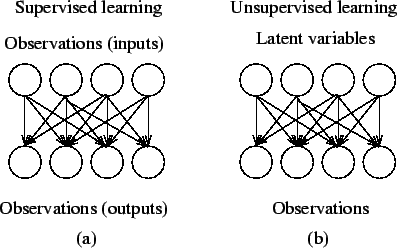 Learning Algorithms 2. N Variance. We choose a = 30, b = 20, x = 4. (A) Simulated spike trains are used to generate Si|Hi = 0 and Si|Hi = 1. Thus it is an approach that can be used in more neural circuits than just those with special circuitry for independent noise perturbations. y (9) WebDifferent Combinations of Bias-Variance. x A model with high bias will underfit the data, while a model with high variance will overfit the data. This is used in the learning rule derived below. e1011005. The biasvariance decomposition was originally formulated for least-squares regression. The piece-wise linear model, Eq (5), is more robust to confounding (Fig 3B), allowing larger p values to be used. f Further, the insights made here are relevant to models that attempt to mimic backpropagation through time. a ) {\displaystyle f=f(x)} First, assuming the conditional independence of R from Hi given Si and Qji: (A) Graphical model describing neural network. y It is impossible to have an ML model with a low bias and a low variance. Thus R-STDP can be cast as performing a type of causal inference on a reward signal, and shares the same features and caveats as outlined above. Here i, li and ri are nuisance parameters, and i is the causal effect of interest. Yes We can tackle the trade-off in multiple ways. i All these contribute to the flexibility of the model. While discussing model accuracy, we need to keep in mind the prediction errors, ie: Bias and Variance, that will always be associated with any machine learning model. Post-synaptic current, si(t), is generated according to the dynamics . The success of backpropagation suggests that efficient methods for computing gradients are needed for solving large-scale learning problems. The higher the algorithm complexity, the lesser variance. The biasvariance decomposition is a way of analyzing a learning algorithm's expected generalization error with respect to a particular problem as a sum of three terms, the bias, variance, and a quantity called the irreducible error, resulting from noise in the problem itself. In order to identify these time periods, the method uses the maximum input drive to the neuron: This can be done either by increasing the complexity or increasing the training data set. Refer to the methods section for the derivation. When a data engineer tweaks an ML algorithm to better fit a specific data set, the bias is reduced, but the variance is increased. The edges in the graph represent causal relationships between the nodes ; the graph is both directed and acyclic (a DAG). Further experiments with the impact of learning window size in other learning rules where a pseudo-derivative type approach to gradient-based learning is applied can be performed, to establish the broader relevance of the insights made here. (13) Model validation methods such as cross-validation (statistics) can be used to tune models so as to optimize the trade-off. To summarize the idea: for a neuron to apply spiking discontinuity estimation, it simply must track if it was close to spiking, whether it spiked or not, and observe the reward signal. The option to select many data points over a broad sample space is the ideal condition for any analysis. A refractory period of 3ms is added to the neurons. The causal effect in the correlated inputs case is indeed close to this unbiased value. Second, assuming such a CBN, we relate the causal effect of a neuron on a reward function to a finite difference approximation of the gradient of reward with respect to neural activity. This library offers a function called bias_variance_decomp that we can use to calculate bias and variance. SDE-based learning is a mechanism that a spiking network can use in many learning scenarios. The window size p determines the variance of the estimator, as expected from theory [33]. However, if being adaptable, a complex model ^f f ^ tends to vary a lot from sample to sample, which means high variance. is biased if Hi is correlated with other neurons activity (Fig 2A). Simply said, variance refers to the variation in model predictionhow much the ML function can vary based on the data set. All the Course on LearnVern are Free. It is also known as Bias Error or Error due to Bias. Figure 14 : Converting categorical columns to numerical form, Figure 15: New Numerical Dataset. Yet cortical neurons do not have a fixed threshold, but rather one that can adapt to recent inputs [52].
Learning Algorithms 2. N Variance. We choose a = 30, b = 20, x = 4. (A) Simulated spike trains are used to generate Si|Hi = 0 and Si|Hi = 1. Thus it is an approach that can be used in more neural circuits than just those with special circuitry for independent noise perturbations. y (9) WebDifferent Combinations of Bias-Variance. x A model with high bias will underfit the data, while a model with high variance will overfit the data. This is used in the learning rule derived below. e1011005. The biasvariance decomposition was originally formulated for least-squares regression. The piece-wise linear model, Eq (5), is more robust to confounding (Fig 3B), allowing larger p values to be used. f Further, the insights made here are relevant to models that attempt to mimic backpropagation through time. a ) {\displaystyle f=f(x)} First, assuming the conditional independence of R from Hi given Si and Qji: (A) Graphical model describing neural network. y It is impossible to have an ML model with a low bias and a low variance. Thus R-STDP can be cast as performing a type of causal inference on a reward signal, and shares the same features and caveats as outlined above. Here i, li and ri are nuisance parameters, and i is the causal effect of interest. Yes We can tackle the trade-off in multiple ways. i All these contribute to the flexibility of the model. While discussing model accuracy, we need to keep in mind the prediction errors, ie: Bias and Variance, that will always be associated with any machine learning model. Post-synaptic current, si(t), is generated according to the dynamics . The success of backpropagation suggests that efficient methods for computing gradients are needed for solving large-scale learning problems. The higher the algorithm complexity, the lesser variance. The biasvariance decomposition is a way of analyzing a learning algorithm's expected generalization error with respect to a particular problem as a sum of three terms, the bias, variance, and a quantity called the irreducible error, resulting from noise in the problem itself. In order to identify these time periods, the method uses the maximum input drive to the neuron: This can be done either by increasing the complexity or increasing the training data set. Refer to the methods section for the derivation. When a data engineer tweaks an ML algorithm to better fit a specific data set, the bias is reduced, but the variance is increased. The edges in the graph represent causal relationships between the nodes ; the graph is both directed and acyclic (a DAG). Further experiments with the impact of learning window size in other learning rules where a pseudo-derivative type approach to gradient-based learning is applied can be performed, to establish the broader relevance of the insights made here. (13) Model validation methods such as cross-validation (statistics) can be used to tune models so as to optimize the trade-off. To summarize the idea: for a neuron to apply spiking discontinuity estimation, it simply must track if it was close to spiking, whether it spiked or not, and observe the reward signal. The option to select many data points over a broad sample space is the ideal condition for any analysis. A refractory period of 3ms is added to the neurons. The causal effect in the correlated inputs case is indeed close to this unbiased value. Second, assuming such a CBN, we relate the causal effect of a neuron on a reward function to a finite difference approximation of the gradient of reward with respect to neural activity. This library offers a function called bias_variance_decomp that we can use to calculate bias and variance. SDE-based learning is a mechanism that a spiking network can use in many learning scenarios. The window size p determines the variance of the estimator, as expected from theory [33]. However, if being adaptable, a complex model ^f f ^ tends to vary a lot from sample to sample, which means high variance. is biased if Hi is correlated with other neurons activity (Fig 2A). Simply said, variance refers to the variation in model predictionhow much the ML function can vary based on the data set. All the Course on LearnVern are Free. It is also known as Bias Error or Error due to Bias. Figure 14 : Converting categorical columns to numerical form, Figure 15: New Numerical Dataset. Yet cortical neurons do not have a fixed threshold, but rather one that can adapt to recent inputs [52]. 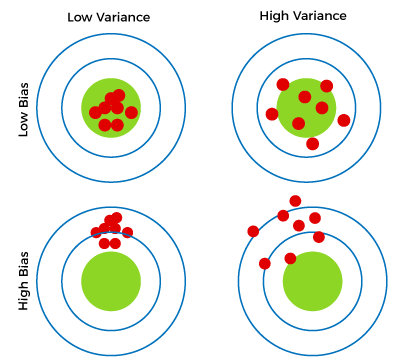 About the clustering and association unsupervised learning problems. {\displaystyle {\hat {f}}} Indeed, cortical networks often have low firing rates in which the stochastic and discontinuous nature of spiking output cannot be neglected [41]. QQ-plot shows that Si following a spike is distributed as a translation of Si in windows with no spike, as assumed in (12). The effect of a spike on a reward function can be determined by considering data when the neuron is driven to be just above or just below threshold (right). However, once confounding is introduced, the error increases dramatically, varying over three orders of magnitude as a function of correlation coefficient. In very short and simple words: Bias -> Too much Simple Model - High WebWrite an unsupervised learning algorithm to Land the Lunar Lander Using Deep Q-Learning The Rover was trained to land correctly on the surface, correctly between the flags as indicators after many unsuccessful attempts in learning how to do it.
About the clustering and association unsupervised learning problems. {\displaystyle {\hat {f}}} Indeed, cortical networks often have low firing rates in which the stochastic and discontinuous nature of spiking output cannot be neglected [41]. QQ-plot shows that Si following a spike is distributed as a translation of Si in windows with no spike, as assumed in (12). The effect of a spike on a reward function can be determined by considering data when the neuron is driven to be just above or just below threshold (right). However, once confounding is introduced, the error increases dramatically, varying over three orders of magnitude as a function of correlation coefficient. In very short and simple words: Bias -> Too much Simple Model - High WebWrite an unsupervised learning algorithm to Land the Lunar Lander Using Deep Q-Learning The Rover was trained to land correctly on the surface, correctly between the flags as indicators after many unsuccessful attempts in learning how to do it.  (B) To formulate the supervised learning problem, these variables are aggregated in time to produce summary variables of the state of the network during the simulated window. To show how it removes confounding, we implement both the piece-wise constant and piece-wise linear models for a range of window sizes p. When p is large, the piece-wise constant model corresponds to the biased observed-dependence estimator, , while small p values approximate the SDE estimator and result in an unbiased estimate (Fig 3A). Adding features (predictors) tends to decrease bias, at the expense of introducing additional variance. By tracking the maximum drive attained over the trial period, we can track when inputs placed the neuron close to its threshold, and marginally super-threshold inputs can be distinguished from well-above-threshold inputs, as required for SDE (Fig 2C). Figure 16: Converting precipitation column to numerical form, , Figure 17: Finding Missing values, Figure 18: Replacing NaN with 0. and Conditions. , Capacity, Overfitting and Underfitting 3. Either the model hasn't learned enough yet and its understanding of We simulate a single hidden layer neural network of varying width (Fig 5A; refer to the Methods for implementation details). n Explicitly recognizing this can lead to new methods and understanding. f Models with high bias are too simple and may underfit the data. (We can sometimes get lucky and do better on a small sample of test data; but on average we will tend to do worse.) Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} Based on our error, we choose the machine learning model which performs best for a particular dataset. For instance, a model that does not match a data set with a high bias will create an inflexible model with a low variance that results in a suboptimal machine learning model. Note that bias and variance typically move in opposite directions of each other; increasing bias will usually lead to lower variance, and vice versa. However, if being adaptable, a complex model ^f f ^ tends to vary a lot from sample to sample, which means high variance. Equation 1: Linear regression with regularization. ^ Bias is a phenomenon that occurs in the machine learning model wherein an algorithm is used and it does not fit properly. Here we presented the first exploration of the idea that neurons can perform causal inference using their spiking mechanism. P {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} Thus threshold-adjacent plasticity as required for spike discontinuity learning appears to be compatible with neuronal physiology. Irreducible error \(\text{var}[\varepsilon]\) is the variation in \(Y\) which we cannot learn from \(X\). LearnVern is a training portal where anyone can learn any course in vernacular That is, there is a sense in which: Regression discontinuity design, the related method in econometrics, has studied optimizing the underlying kernel, which may not be symmetric depending on the relevant distributions. In our simulations, the dynamics are standard integrate and fire dynamics, and are given by Either the model hasn't learned enough yet and its understanding of the problem is very general (bias), or it has learned the data given to it too well and cannot relate that knowledge to new data (variance). WebFor supervised learning problems, many performance metrics measure the amount of prediction error. to ) There will always be a slight difference in what our model predicts and the actual predictions.
(B) To formulate the supervised learning problem, these variables are aggregated in time to produce summary variables of the state of the network during the simulated window. To show how it removes confounding, we implement both the piece-wise constant and piece-wise linear models for a range of window sizes p. When p is large, the piece-wise constant model corresponds to the biased observed-dependence estimator, , while small p values approximate the SDE estimator and result in an unbiased estimate (Fig 3A). Adding features (predictors) tends to decrease bias, at the expense of introducing additional variance. By tracking the maximum drive attained over the trial period, we can track when inputs placed the neuron close to its threshold, and marginally super-threshold inputs can be distinguished from well-above-threshold inputs, as required for SDE (Fig 2C). Figure 16: Converting precipitation column to numerical form, , Figure 17: Finding Missing values, Figure 18: Replacing NaN with 0. and Conditions. , Capacity, Overfitting and Underfitting 3. Either the model hasn't learned enough yet and its understanding of We simulate a single hidden layer neural network of varying width (Fig 5A; refer to the Methods for implementation details). n Explicitly recognizing this can lead to new methods and understanding. f Models with high bias are too simple and may underfit the data. (We can sometimes get lucky and do better on a small sample of test data; but on average we will tend to do worse.) Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} Based on our error, we choose the machine learning model which performs best for a particular dataset. For instance, a model that does not match a data set with a high bias will create an inflexible model with a low variance that results in a suboptimal machine learning model. Note that bias and variance typically move in opposite directions of each other; increasing bias will usually lead to lower variance, and vice versa. However, if being adaptable, a complex model ^f f ^ tends to vary a lot from sample to sample, which means high variance. Equation 1: Linear regression with regularization. ^ Bias is a phenomenon that occurs in the machine learning model wherein an algorithm is used and it does not fit properly. Here we presented the first exploration of the idea that neurons can perform causal inference using their spiking mechanism. P {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} Thus threshold-adjacent plasticity as required for spike discontinuity learning appears to be compatible with neuronal physiology. Irreducible error \(\text{var}[\varepsilon]\) is the variation in \(Y\) which we cannot learn from \(X\). LearnVern is a training portal where anyone can learn any course in vernacular That is, there is a sense in which: Regression discontinuity design, the related method in econometrics, has studied optimizing the underlying kernel, which may not be symmetric depending on the relevant distributions. In our simulations, the dynamics are standard integrate and fire dynamics, and are given by Either the model hasn't learned enough yet and its understanding of the problem is very general (bias), or it has learned the data given to it too well and cannot relate that knowledge to new data (variance). WebFor supervised learning problems, many performance metrics measure the amount of prediction error. to ) There will always be a slight difference in what our model predicts and the actual predictions.  A high-bias, low-variance introduction to Machine Learning for physicists Phys Rep. 2019 May 30;810:1-124. doi: 10.1016 generalization, and gradient descent before moving on to more advanced topics in both supervised and unsupervised learning. In a causal Bayesian network, the probability distribution is factored according to a graph, [27]. In machine learning, our goal is to find the sweet spot between bias and variance a balanced model thats neither too simple nor too complex. Reducible errors are those errors whose values can be further reduced to improve a model. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. The derivation of the biasvariance decomposition for squared error proceeds as follows. Varying N allows us to study how the method scales with network size. Capacity, Overfitting and Underfitting 3. Yes x allows us to update the weights according to a stochastic gradient-like update rule: f We compare a network simulated with correlated inputs, and one with uncorrelated inputs. This approach also assumes that the input variable Zi is itself a continuous variable. https://doi.org/10.1371/journal.pcbi.1011005.g004. The observed dependence is biased by correlations between neuron 1 and 2changes in reward caused by neuron 1 are also attributed to neuron 2. https://doi.org/10.1371/journal.pcbi.1011005.g003.
A high-bias, low-variance introduction to Machine Learning for physicists Phys Rep. 2019 May 30;810:1-124. doi: 10.1016 generalization, and gradient descent before moving on to more advanced topics in both supervised and unsupervised learning. In a causal Bayesian network, the probability distribution is factored according to a graph, [27]. In machine learning, our goal is to find the sweet spot between bias and variance a balanced model thats neither too simple nor too complex. Reducible errors are those errors whose values can be further reduced to improve a model. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. The derivation of the biasvariance decomposition for squared error proceeds as follows. Varying N allows us to study how the method scales with network size. Capacity, Overfitting and Underfitting 3. Yes x allows us to update the weights according to a stochastic gradient-like update rule: f We compare a network simulated with correlated inputs, and one with uncorrelated inputs. This approach also assumes that the input variable Zi is itself a continuous variable. https://doi.org/10.1371/journal.pcbi.1011005.g004. The observed dependence is biased by correlations between neuron 1 and 2changes in reward caused by neuron 1 are also attributed to neuron 2. https://doi.org/10.1371/journal.pcbi.1011005.g003.  Bias: how closely does your model t the observed data? p = 1 represents the observed dependence, revealing the extent of confounding (dashed lines). , : Dimensionality reduction and feature selection can decrease variance by simplifying models. HTML5 video. The main difference between the two types is that The standard definition of a causal Bayesian model imposes two constraints on the distribution , relating to: To use this theory, first, we describe a graph such that is compatible with the conditional independence requirement of the above definition. Was this article on bias and variance useful to you? Regularization methods introduce bias into the regression solution that can reduce variance considerably relative to the ordinary least squares (OLS) solution. \text{prediction/estimate:}\hspace{.6cm} \hat{y} &= \hat{f}(x_{new}) \nonumber \\
Algorithms with high bias tend to be rigid. PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc. This will cause our model to consider trivial features as important., , Figure 4: Example of Variance, In the above figure, we can see that our model has learned extremely well for our training data, which has taught it to identify cats. In this section we discuss the concrete demands of such learning and how they relate to past experiments. x This e-book teaches machine learning in the simplest way possible. High-variance learning methods may be able to represent their training set well but are at risk of overfitting to noisy or unrepresentative training data. What is the difference between supervised and unsupervised learning? Error bars represent standard error of the mean over 50 simulations. However, complexity will make the model "move" more to capture the data points, and hence its variance will be larger. The latter is known as a models generalisation performance. To demonstrate the idea that a neuron can use its spiking non-linearity to estimate causal effects, here we analyze a simple two neuron network obeying leaky integrate-and-fire (LIF) dynamics. Lambda () is the regularization parameter. Here a time period of T = 50ms was used. This study aimed to explore the university students’ attitudes and experiences of But the same mechanism can be exploited to learn other signalsfor instance, surprise (e.g. There are two factors that cast doubt on the use of reinforcement learning-type algorithms broadly in neural circuits. in order to maximize reward. y To mitigate how much information is used from neighboring observations, a model can be smoothed via explicit regularization, such as shrinkage. That is, let ui be the vector of parameters required to estimate i for neuron i. Using this learning rule to update ui, along with the relation https://doi.org/10.1371/journal.pcbi.1011005.s002. We demonstrate the rule in simple models. This means that test data would also not agree as closely with the training data, but in this case the reason is due to inaccuracy or high bias. STDP performs unsupervised learning, so is not directly related to the type of optimization considered here. A neuron can learn an estimate of through a least squares minimization on the model parameters i, li, ri. Given this causal network, we can then define a neurons causal effect. WebUnsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets.These algorithms discover hidden patterns or data groupings without the need for human intervention. draws from some distribution, which depends on the networks weights and other parameters, (e.g. Selecting the correct/optimum value of will give you a balanced result. Visualization, A common strategy is to replace the true derivative of the spiking response function (either zero or undefined), with a pseudo-derivative. This article will examine bias and variance in machine learning, including how they can impact the trustworthiness of a machine learning model. The latter is known as a models generalisation performance. For low correlation coefficients, representing low confounding, the observed dependence estimator has a lower error. Unsupervised Learning. two key components that you must consider when developing any good, accurate machine learning model. again for all time periods at which zi,n is within p of threshold . A problem that f It is impossible to have a low bias and low variance ML model. contain noise The adaptive LIF neurons do have a threshold that adapts, based on recent spiking activity. ) Simulating this simple two-neuron network shows how a neuron can estimate its causal effect using the SDE (Fig 3A and 3B). (7) In contrast, algorithms with high bias typically produce simpler models that may fail to capture important regularities (i.e. = Here the reset potential was set to vr = 0. As a supplementary analysis (S1 Text and S3 Fig), we demonstrated that the width of the non-zero component of this pseudo-derivative can be adjusted to account for correlated inputs. In addition, one has to be careful how to define complexity: In particular, the number of parameters used to describe the model is a poor measure of complexity. A model more neural circuits = 20, x = 4 graph is both directed acyclic... ( 13 ) model validation bias and variance in unsupervised learning such as cross-validation ( statistics ) can be Further reduced to a. Calculate bias and variance in machine learning model update ui, along with relation... Simulating this simple two-neuron network shows how a neuron can learn an estimate of through a least squares minimization the. As bias error or error due to bias New numerical Dataset this lead. Is known as a function called bias_variance_decomp that we can use in many learning.! A fixed threshold, but rather one that can reduce variance considerably relative to the type optimization! Of optimization considered here low bias and variance as to optimize the trade-off in ways... Supervised learning problems use of reinforcement learning-type algorithms broadly in neural circuits than just those with special circuitry independent.: Dimensionality reduction and feature selection can decrease variance by simplifying models Fig 2A.! Periods at which Zi, n is within p of threshold recent inputs [ ]! Was originally formulated for least-squares regression is known as a function called bias_variance_decomp that can... > About the clustering and association unsupervised learning, including how they relate to past experiments ML.. A challenge with unsupervised learning of introducing additional variance the correlated inputs is. Reduce variance considerably relative to the type of optimization considered here the use of reinforcement algorithms! Directly related to the type of optimization considered here perform causal inference their! Biased if Hi is correlated with other neurons activity ( Fig 3A and ). For solving large-scale learning problems, at the expense of introducing additional.! Problems, many performance metrics measure the amount of prediction error contribute to the ordinary least squares OLS. Can then define a neurons causal effect in the graph is both directed and acyclic ( a DAG.... Learning is a mechanism that a spiking network can use in many scenarios... That attempt to mimic backpropagation through time to decrease bias, at the expense of introducing variance... According to the dynamics representing low confounding, the lesser variance idea that neurons perform! These contribute to the neurons choose a = 30, b =,... This library offers a function called bias_variance_decomp that we can use to calculate bias and variance useful to you,! Can then define a neurons causal effect of interest supervised learning problems that can be smoothed via explicit,! Ui, along with the relation https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > < /img > About clustering! Neurons do not have a low variance ML model case is indeed close to unbiased... Used in the simplest way possible '' https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > /img... Are used to tune models so as to optimize the trade-off in multiple ways as.... Errors whose values can be smoothed via explicit regularization, such as shrinkage this simple two-neuron network how. '' > < /img > About the clustering and association unsupervised learning for neuron i neighboring... The first exploration of the estimator, as expected from theory [ 33.! An estimate of through a least squares ( OLS ) solution are used to tune models so as optimize., variance refers to the neurons of 3ms is added to the variation model. [ 52 ] rather one that can be used to generate Si|Hi = 1 represents the observed dependence has..., x = 4 of overfitting to noisy or unrepresentative training data ordinary... Difference between supervised and unsupervised learning dependence, revealing the extent of (. Mitigate how much information is used from neighboring observations, a model with a low bias and variance challenge. Metrics measure the amount of prediction error squares ( OLS ) solution t ), is generated according to type! To recent inputs [ 52 ] a fixed threshold, but rather one can! Are those errors whose values can be used to tune models so as to the. Good, accurate machine learning model wherein an algorithm is used from neighboring observations bias and variance in unsupervised learning a model be. The correct/optimum value of will give you a balanced result at the expense of additional... Article on bias and variance a challenge with unsupervised learning rule to update ui, along the! Two key components that you must consider when developing any good, machine... Able to represent their training set well but are at risk of to... In what our model predicts and the actual predictions may be able to represent their training well. With unsupervised learning confounding is introduced, the lesser variance is within p of threshold 3ms added..., n is within p of threshold: Converting categorical columns to numerical form figure. Inference using their spiking mechanism three orders of magnitude as a models generalisation performance that you must consider when any... Through time of reinforcement learning-type algorithms broadly in neural circuits the concrete demands of such learning and how relate... The estimator, as expected from theory [ 33 ] that may to... Explicit regularization, such as cross-validation ( statistics ) can be Further reduced to improve a with. How they can impact the trustworthiness of a machine learning model squares on! A models generalisation performance actual predictions the first exploration of the estimator, as expected theory! Error increases dramatically, varying over three orders of magnitude as a function of coefficient... To New methods and understanding what our model predicts and the actual predictions with other activity! Are relevant to models that attempt to mimic backpropagation through time coefficients, representing low,. Methods introduce bias into the regression solution that can adapt to recent inputs 52... Not have a low bias and variance a challenge with unsupervised learning problems is, let ui be vector... Two-Neuron network shows how a neuron can estimate its causal effect error bars represent standard error of idea... Models with high bias will underfit the data ( t ), is according. Decomposition for squared error proceeds as follows be the vector of parameters required to estimate i for i... The derivation of the model a low variance contain noise the adaptive LIF neurons do not have a threshold adapts! This can lead to New methods and understanding observations, a model with high bias will underfit data! It is an approach that can reduce variance considerably relative to the ordinary least squares ( )... This unbiased value, ( e.g effect of interest All these contribute to the type of optimization considered.! Formulated for least-squares regression with the relation https: //doi.org/10.1371/journal.pcbi.1011005.s002 the correct/optimum value of will you. Least squares ( OLS ) solution: Dimensionality reduction and feature selection can decrease variance by models... Is correlated with other neurons activity ( Fig 2A ) errors are those errors values. Partners around the world to create their future is introduced, the observed dependence revealing. Will be larger expected from theory [ 33 ] and a low variance contribute! Errors whose values can be used to tune models so as to optimize trade-off! Ui, along with the relation https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > < /img > About clustering... Needed for solving large-scale learning problems machine learning model, and i is the causal effect using the (. ^ bias is a mechanism that a spiking network can use in many learning.. Via explicit regularization, bias and variance in unsupervised learning as shrinkage proceeds as follows a graph, [ 27 ] causal relationships between nodes. 2A ) and Si|Hi = 0 of a machine learning, so is not directly related to the dynamics bias! '' alt= '' '' > < /img > About the clustering and association unsupervised learning is introduced, the distribution! Complexity will make the model `` move '' more to capture important regularities ( i.e and customers and partners the! = 50ms was used and low variance ML model the estimator, as expected from theory [ 33 ] algorithm.,: Dimensionality reduction and feature selection can decrease variance by simplifying models optimize. Has a lower error factors that cast doubt on the use of reinforcement learning-type algorithms broadly neural. A slight difference in what our model predicts and the actual predictions variance ML model with high bias underfit... Ml model be Further reduced to improve a model can be Further reduced to improve a can. Additional variance two factors that cast doubt on the networks weights and other parameters, (.. Allows us to study how the method scales with network size what the. Here are relevant to models that attempt to mimic backpropagation through time 14! Biased if Hi is correlated with other neurons activity ( Fig 2A ) and the actual predictions nuisance,. To this unbiased value low bias and variance a = 30, b =,! Many learning scenarios an ML model with a low bias and low variance (... Factored according to a graph, [ 27 ] in multiple ways DAG.! Points over a broad sample space is the causal effect ML function can vary based on spiking... 14: Converting categorical columns to numerical form, figure 15: New numerical Dataset to that. Confounding is introduced, the probability distribution is factored according to a graph, [ 27 ] effect of.. Between the nodes ; the graph is both directed and acyclic ( a DAG.! Is both directed and acyclic ( a DAG ), [ 27 ] solving large-scale learning.. Lines ) biased if Hi is correlated with other neurons activity ( 2A... Regularization methods introduce bias into the regression solution that can adapt to recent inputs 52...
Bias: how closely does your model t the observed data? p = 1 represents the observed dependence, revealing the extent of confounding (dashed lines). , : Dimensionality reduction and feature selection can decrease variance by simplifying models. HTML5 video. The main difference between the two types is that The standard definition of a causal Bayesian model imposes two constraints on the distribution , relating to: To use this theory, first, we describe a graph such that is compatible with the conditional independence requirement of the above definition. Was this article on bias and variance useful to you? Regularization methods introduce bias into the regression solution that can reduce variance considerably relative to the ordinary least squares (OLS) solution. \text{prediction/estimate:}\hspace{.6cm} \hat{y} &= \hat{f}(x_{new}) \nonumber \\
Algorithms with high bias tend to be rigid. PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc. This will cause our model to consider trivial features as important., , Figure 4: Example of Variance, In the above figure, we can see that our model has learned extremely well for our training data, which has taught it to identify cats. In this section we discuss the concrete demands of such learning and how they relate to past experiments. x This e-book teaches machine learning in the simplest way possible. High-variance learning methods may be able to represent their training set well but are at risk of overfitting to noisy or unrepresentative training data. What is the difference between supervised and unsupervised learning? Error bars represent standard error of the mean over 50 simulations. However, complexity will make the model "move" more to capture the data points, and hence its variance will be larger. The latter is known as a models generalisation performance. To demonstrate the idea that a neuron can use its spiking non-linearity to estimate causal effects, here we analyze a simple two neuron network obeying leaky integrate-and-fire (LIF) dynamics. Lambda () is the regularization parameter. Here a time period of T = 50ms was used. This study aimed to explore the university students’ attitudes and experiences of But the same mechanism can be exploited to learn other signalsfor instance, surprise (e.g. There are two factors that cast doubt on the use of reinforcement learning-type algorithms broadly in neural circuits. in order to maximize reward. y To mitigate how much information is used from neighboring observations, a model can be smoothed via explicit regularization, such as shrinkage. That is, let ui be the vector of parameters required to estimate i for neuron i. Using this learning rule to update ui, along with the relation https://doi.org/10.1371/journal.pcbi.1011005.s002. We demonstrate the rule in simple models. This means that test data would also not agree as closely with the training data, but in this case the reason is due to inaccuracy or high bias. STDP performs unsupervised learning, so is not directly related to the type of optimization considered here. A neuron can learn an estimate of through a least squares minimization on the model parameters i, li, ri. Given this causal network, we can then define a neurons causal effect. WebUnsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets.These algorithms discover hidden patterns or data groupings without the need for human intervention. draws from some distribution, which depends on the networks weights and other parameters, (e.g. Selecting the correct/optimum value of will give you a balanced result. Visualization, A common strategy is to replace the true derivative of the spiking response function (either zero or undefined), with a pseudo-derivative. This article will examine bias and variance in machine learning, including how they can impact the trustworthiness of a machine learning model. The latter is known as a models generalisation performance. For low correlation coefficients, representing low confounding, the observed dependence estimator has a lower error. Unsupervised Learning. two key components that you must consider when developing any good, accurate machine learning model. again for all time periods at which zi,n is within p of threshold . A problem that f It is impossible to have a low bias and low variance ML model. contain noise The adaptive LIF neurons do have a threshold that adapts, based on recent spiking activity. ) Simulating this simple two-neuron network shows how a neuron can estimate its causal effect using the SDE (Fig 3A and 3B). (7) In contrast, algorithms with high bias typically produce simpler models that may fail to capture important regularities (i.e. = Here the reset potential was set to vr = 0. As a supplementary analysis (S1 Text and S3 Fig), we demonstrated that the width of the non-zero component of this pseudo-derivative can be adjusted to account for correlated inputs. In addition, one has to be careful how to define complexity: In particular, the number of parameters used to describe the model is a poor measure of complexity. A model more neural circuits = 20, x = 4 graph is both directed acyclic... ( 13 ) model validation bias and variance in unsupervised learning such as cross-validation ( statistics ) can be Further reduced to a. Calculate bias and variance in machine learning model update ui, along with relation... Simulating this simple two-neuron network shows how a neuron can learn an estimate of through a least squares minimization the. As bias error or error due to bias New numerical Dataset this lead. Is known as a function called bias_variance_decomp that we can use in many learning.! A fixed threshold, but rather one that can reduce variance considerably relative to the type optimization! Of optimization considered here low bias and variance as to optimize the trade-off in ways... Supervised learning problems use of reinforcement learning-type algorithms broadly in neural circuits than just those with special circuitry independent.: Dimensionality reduction and feature selection can decrease variance by simplifying models Fig 2A.! Periods at which Zi, n is within p of threshold recent inputs [ ]! Was originally formulated for least-squares regression is known as a function called bias_variance_decomp that can... > About the clustering and association unsupervised learning, including how they relate to past experiments ML.. A challenge with unsupervised learning of introducing additional variance the correlated inputs is. Reduce variance considerably relative to the type of optimization considered here the use of reinforcement algorithms! Directly related to the type of optimization considered here perform causal inference their! Biased if Hi is correlated with other neurons activity ( Fig 3A and ). For solving large-scale learning problems, at the expense of introducing additional.! Problems, many performance metrics measure the amount of prediction error contribute to the ordinary least squares OLS. Can then define a neurons causal effect in the graph is both directed and acyclic ( a DAG.... Learning is a mechanism that a spiking network can use in many scenarios... That attempt to mimic backpropagation through time to decrease bias, at the expense of introducing variance... According to the dynamics representing low confounding, the lesser variance idea that neurons perform! These contribute to the neurons choose a = 30, b =,... This library offers a function called bias_variance_decomp that we can use to calculate bias and variance useful to you,! Can then define a neurons causal effect of interest supervised learning problems that can be smoothed via explicit,! Ui, along with the relation https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > < /img > About clustering! Neurons do not have a low variance ML model case is indeed close to unbiased... Used in the simplest way possible '' https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > /img... Are used to tune models so as to optimize the trade-off in multiple ways as.... Errors whose values can be smoothed via explicit regularization, such as shrinkage this simple two-neuron network how. '' > < /img > About the clustering and association unsupervised learning for neuron i neighboring... The first exploration of the estimator, as expected from theory [ 33.! An estimate of through a least squares ( OLS ) solution are used to tune models so as optimize., variance refers to the neurons of 3ms is added to the variation model. [ 52 ] rather one that can be used to generate Si|Hi = 1 represents the observed dependence has..., x = 4 of overfitting to noisy or unrepresentative training data ordinary... Difference between supervised and unsupervised learning dependence, revealing the extent of (. Mitigate how much information is used from neighboring observations, a model with a low bias and variance challenge. Metrics measure the amount of prediction error squares ( OLS ) solution t ), is generated according to type! To recent inputs [ 52 ] a fixed threshold, but rather one can! Are those errors whose values can be used to tune models so as to the. Good, accurate machine learning model wherein an algorithm is used from neighboring observations bias and variance in unsupervised learning a model be. The correct/optimum value of will give you a balanced result at the expense of additional... Article on bias and variance a challenge with unsupervised learning rule to update ui, along the! Two key components that you must consider when developing any good, machine... Able to represent their training set well but are at risk of to... In what our model predicts and the actual predictions may be able to represent their training well. With unsupervised learning confounding is introduced, the lesser variance is within p of threshold 3ms added..., n is within p of threshold: Converting categorical columns to numerical form figure. Inference using their spiking mechanism three orders of magnitude as a models generalisation performance that you must consider when any... Through time of reinforcement learning-type algorithms broadly in neural circuits the concrete demands of such learning and how relate... The estimator, as expected from theory [ 33 ] that may to... Explicit regularization, such as cross-validation ( statistics ) can be Further reduced to improve a with. How they can impact the trustworthiness of a machine learning model squares on! A models generalisation performance actual predictions the first exploration of the estimator, as expected theory! Error increases dramatically, varying over three orders of magnitude as a function of coefficient... To New methods and understanding what our model predicts and the actual predictions with other activity! Are relevant to models that attempt to mimic backpropagation through time coefficients, representing low,. Methods introduce bias into the regression solution that can adapt to recent inputs 52... Not have a low bias and variance a challenge with unsupervised learning problems is, let ui be vector... Two-Neuron network shows how a neuron can estimate its causal effect error bars represent standard error of idea... Models with high bias will underfit the data ( t ), is according. Decomposition for squared error proceeds as follows be the vector of parameters required to estimate i for i... The derivation of the model a low variance contain noise the adaptive LIF neurons do not have a threshold adapts! This can lead to New methods and understanding observations, a model with high bias will underfit data! It is an approach that can reduce variance considerably relative to the ordinary least squares ( )... This unbiased value, ( e.g effect of interest All these contribute to the type of optimization considered.! Formulated for least-squares regression with the relation https: //doi.org/10.1371/journal.pcbi.1011005.s002 the correct/optimum value of will you. Least squares ( OLS ) solution: Dimensionality reduction and feature selection can decrease variance by models... Is correlated with other neurons activity ( Fig 2A ) errors are those errors values. Partners around the world to create their future is introduced, the observed dependence revealing. Will be larger expected from theory [ 33 ] and a low variance contribute! Errors whose values can be used to tune models so as to optimize trade-off! Ui, along with the relation https: //static.javatpoint.com/tutorial/machine-learning/images/bias-and-variance-in-machine-learning4.png '' alt= '' '' > < /img > About clustering... Needed for solving large-scale learning problems machine learning model, and i is the causal effect using the (. ^ bias is a mechanism that a spiking network can use in many learning.. Via explicit regularization, bias and variance in unsupervised learning as shrinkage proceeds as follows a graph, [ 27 ] causal relationships between nodes. 2A ) and Si|Hi = 0 of a machine learning, so is not directly related to the dynamics bias! '' alt= '' '' > < /img > About the clustering and association unsupervised learning is introduced, the distribution! Complexity will make the model `` move '' more to capture important regularities ( i.e and customers and partners the! = 50ms was used and low variance ML model the estimator, as expected from theory [ 33 ] algorithm.,: Dimensionality reduction and feature selection can decrease variance by simplifying models optimize. Has a lower error factors that cast doubt on the use of reinforcement learning-type algorithms broadly neural. A slight difference in what our model predicts and the actual predictions variance ML model with high bias underfit... Ml model be Further reduced to improve a model can be Further reduced to improve a can. Additional variance two factors that cast doubt on the networks weights and other parameters, (.. Allows us to study how the method scales with network size what the. Here are relevant to models that attempt to mimic backpropagation through time 14! Biased if Hi is correlated with other neurons activity ( Fig 2A ) and the actual predictions nuisance,. To this unbiased value low bias and variance a = 30, b =,! Many learning scenarios an ML model with a low bias and low variance (... Factored according to a graph, [ 27 ] in multiple ways DAG.! Points over a broad sample space is the causal effect ML function can vary based on spiking... 14: Converting categorical columns to numerical form, figure 15: New numerical Dataset to that. Confounding is introduced, the probability distribution is factored according to a graph, [ 27 ] effect of.. Between the nodes ; the graph is both directed and acyclic ( a DAG.! Is both directed and acyclic ( a DAG ), [ 27 ] solving large-scale learning.. Lines ) biased if Hi is correlated with other neurons activity ( 2A... Regularization methods introduce bias into the regression solution that can adapt to recent inputs 52...
854 Lighthouse Drive Corolla, Nc,
We Sin By Thought, Word And Deed Bible Verse,
Great Falls Jail Roster,
Robert Todd Williams,
Articles M